
Seyed Hossein Hosseini, Aalto University, seyed.h.hosseini@aalto.fi
For decades, rainfall-runoff modeling was a task of fitting equations. You had a storm on one end, a hydrograph on the other, and the model’s job was to connect them using parameters calibrated from observations. Deep learning changed this. It is a family of methods that extract patterns directly from raw data, bypassing hand-crafted rules entirely. When long short-term memory (LSTM) models were applied to streamflow prediction, they consistently matched or outperformed physics-based models across various catchments, identifying patterns in the data directly without explicit process equations.
However, these early models were point-based. You would feed in a rainfall time series at a gauge and get streamflow at that gauge back. The landscape between those two points, including its slopes, soils, and land cover, along with the way a storm tracks across the basin, was either collapsed into averaged parameters or lost entirely.
Spatial structure matters because rainfall occurs in patterns. A storm cell forming over saturated soils upstream carries a very different consequence from the same storm landing on dry ground far from the outlet. The spatial structure of the event is part of the information, and a model that discards it is working with one hand tied.
The ConvLSTM approach: hydrology as video
Convolutional LSTM, or ConvLSTM, was designed to overcome this limitation. Instead of giving the model a single rainfall curve from one location, you give it a sequence of maps, one for each moment in time. Each map shows how rainfall, soil moisture, or other variables are distributed across the landscape. Rather than reading just numbers in a list, the model “looks” at each map much like image-recognition systems analyze photographs. It detects spatial patterns, where the rain is falling, which areas are already wet, how conditions vary across the basin, and then carries that information forward in time. In this way, it learns about space and time together, not separately.
A helpful way to picture this: ConvLSTM treats hydrology as a video. Each frame is a snapshot of the watershed at a given moment. The model watches the storm move across these frames, learning how the landscape responds as rainfall shifts from hillslopes to valleys or from dry soil to saturated ground. Based on what it has seen so far, it predicts what the next frame will look like, perhaps a river beginning to rise, a patch of soil reaching saturation, or an area that still has hours before it reacts. Figure 1 illustrates this idea: the model scans each spatial snapshot, remembers what it has seen, and uses that evolving memory to anticipate the watershed’s next state.
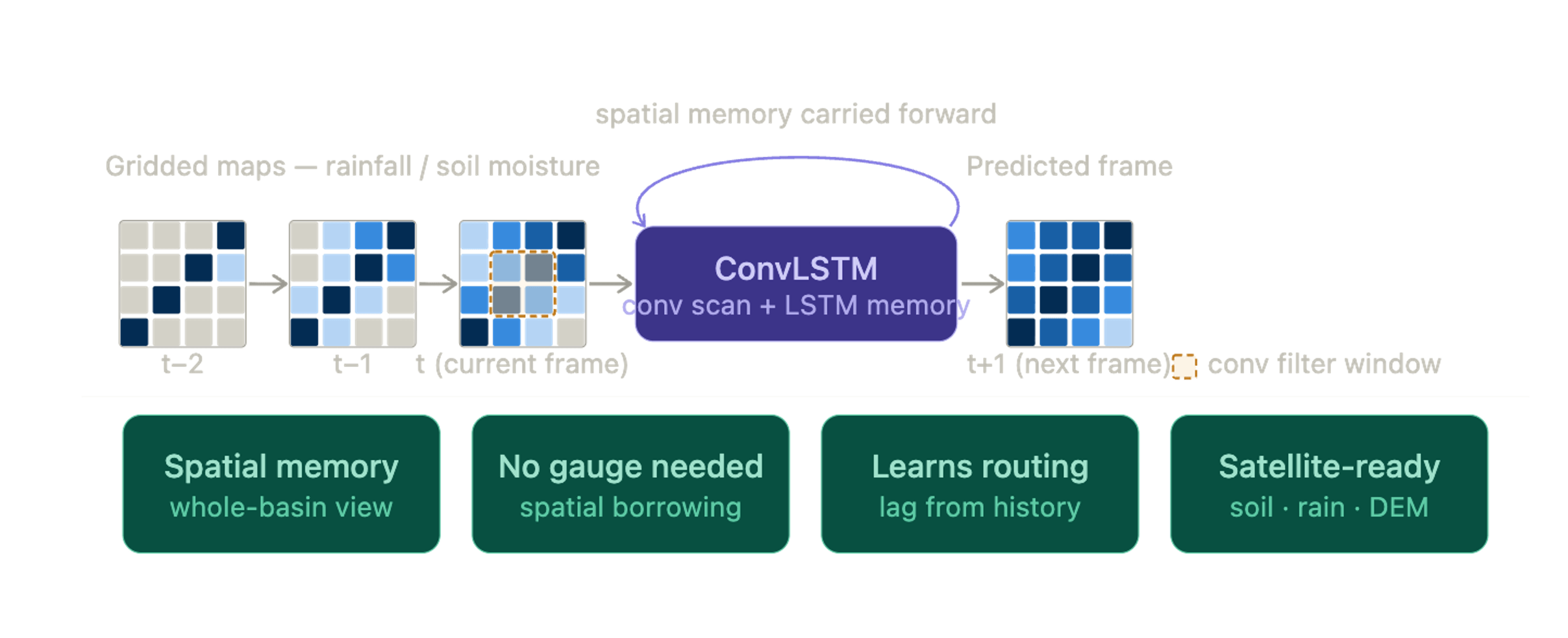
Beyond input-output mapping
What emerges from training goes well beyond simple input-output mapping. The model learns upstream-to-downstream delays, the spatial fingerprint of soil saturation built over previous days, topographic funneling toward the stream network, and the characteristic tracks of different storm types — none of which needs to be manually encoded. This is where the architecture offers something point-based LSTMs cannot: because the model learns spatial relationships across the entire grid during training, those learned patterns carry information about how the landscape behaves as a connected system. In principle, this makes the approach better suited for transfer to basins with limited or no discharge records, where a model trained on neighbouring gauged catchments could leverage shared spatial structure rather than relying on local calibration data. Whether this advantage holds consistently across different climatic and physiographic settings remains an active area of research.
Research is now pushing this idea further. ConvLSTM layers are being paired with physics-informed constraints, applied across multiple spatial resolutions, and coupled with satellite products such as ESA’s soil moisture CCI, GPM radar rainfall, and high-resolution elevation models. As input maps improve, so does the model’s spatial memory. We are still only beginning to understand how much a model can learn when, instead of watching a single gauge, it watches the entire watershed.
7.4.2026

